
机器人视觉应用按照安装方式分为固定式和机持式,实际上无论是固定式和机持式,对于二维视觉应用来说,整个流程和使用实则是一样的,因为机持式只是机器人每次在一个固定的位置拍照,就跟固定式情况下拍照一样。
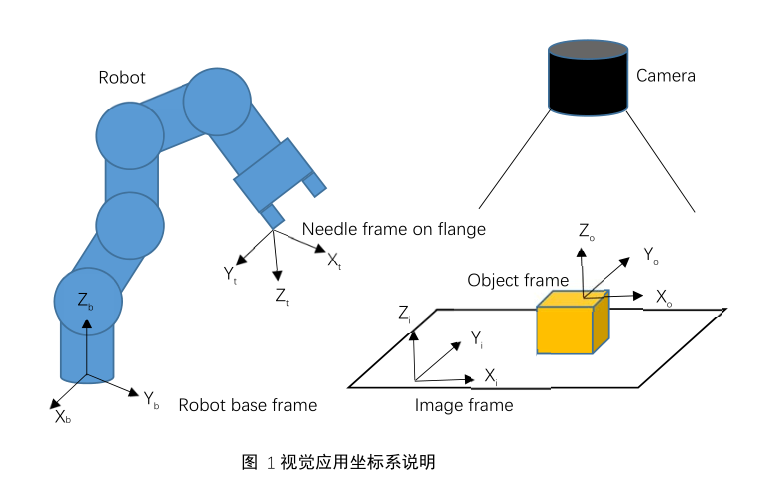
专业术语:路点、位姿,坐标系它们实则都代表着三维空间下的坐标系。一个坐标系由位置和姿态两部分构成,例如我们的 V 变量 X,Y,Z,Rx,Ry,Rz,其中 X,Y,Z 代表坐标系的原点,而 Rx,Ry,Rz 则代表着坐标系绕原点的姿态变化。
这章介绍的机器人视觉应用的主要是针对二维视觉场景下的手眼标定过程,但其标定是在三维空间上进行,并没有做任何模型的简化,因此实则也适用于三维视觉的标定,是一种通用的标定方式
1、在拍照位进行棋盘标定,将物理坐标与图像坐标(单位和位置关系)匹配好,也即图像的像素点坐标(u,v)与图像坐标上(x i ,y i )的对应关系。
2、给机器人末端上装一个针尖,或者挑选一个尖点出来(只要求尖点跟机器人末端法兰相对固定即可),利用 4 点或者 7 点法识别出 TCP。
3、利用针尖 TCP 创建图像坐标系(Image frame)为用户坐标系,此时图像坐标系相对于机器人基座坐标系(Robot base frame)的关系就变成已知了 T i->b ;
4、此时机器人的 TCP 可以切换成机器人正常运行时需要的 TCP(也可不改变),将被定为的物体放入相机视野范围之内,触发拍照,并获取物体在图像坐标系下的位姿 T o->i (图像模板中的识别中心不要求是抓取中心,只要求每次拍照时模板匹配到的中心是物体上的同一个位置即可),而图像坐标系或者用户坐标系相对于机器人基座的位姿 T i->b 在第 3 步已知了。那么通过 PoseMul(T i->b ,T 0->i )可以得到物体相对于机器人基座的位姿 T o->b。
5、保持第 4 步中物体被拍时的位置不动,将机器人 Jog 到相应的抓取位置,记录当前 TCP 的数据 T t->b , 根据 PoseMul(PoseInv(T o->b ),T t->b )可以得到抓取位姿 TCP 相对于物体位姿的相对位姿关系 T t->o ,这个相对位姿关系就是手眼标定的结果。它保证了无论物体实际运行中摆出什么样的姿态,机器人 TCP 相对于物体这个局部坐标系而言,抓取的位姿是一样的。脑补一下物体在任意姿态下,我们要正确抓取他们实则就是我的抓手与物体相对位姿关系一样。
6、运行:运行时,将物体摆放在视野范围之内,触发相机拍照得到物体相对于图像坐标系的数据 T'o->i ,根据 PoseMul(T i->b , T'o->i )即可得到物体实际位姿在机器人坐标系下的位姿 T'o->b ,在第 5 步中辨识得到的机器人 TCP 相对于物体的相对位姿是 T t->o ,因此根据 PoseMul(T'o->b , T t->o )即可得到机器人 TCP 相对于机器人基座的位姿,这个就是 MOVL 需要去走的位姿。






